Top 5 Redis Alternatives (2026)
On this page
Redis has been the default in-memory store for over a decade, but the ground has shifted. The 2024 license change from BSD to SSPL/RSAL (and now AGPLv3 in Redis 8) pushed AWS, Google, and the Linux Foundation to fork it as Valkey, managed Redis bills keep climbing as workloads grow, and a new generation of frontend-first apps wants a key-value store that doesn't require a backend at all.
This article walks through five Redis alternatives — from drop-in forks to fully managed serverless databases to browser-native cloud KV — so you can pick the one that actually matches your stack and your budget.
1. Puter.js
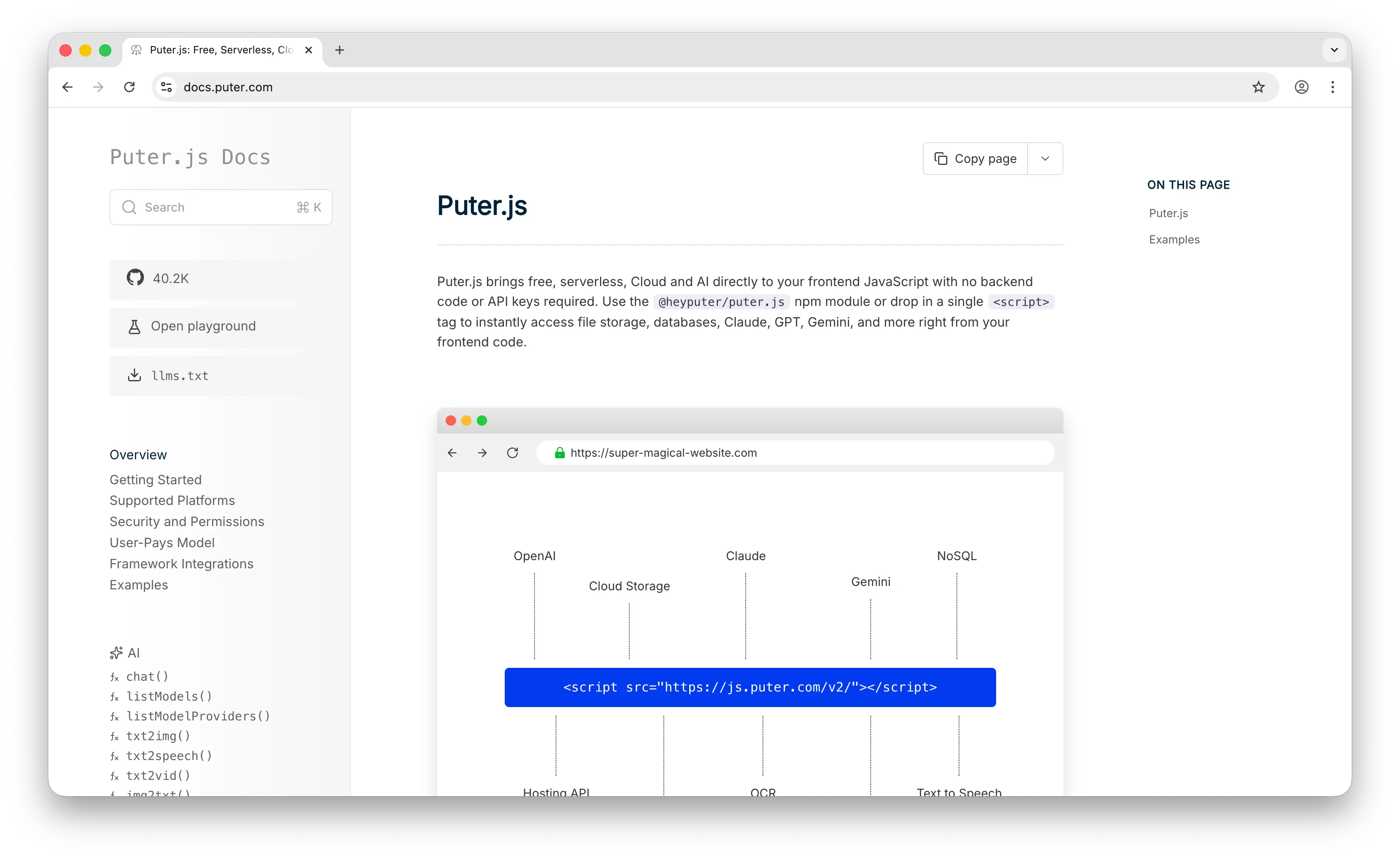
Puter.js is a JavaScript library that exposes a cloud key-value store, file storage, AI, and authentication through a single puter object you drop into the browser with a script tag. There's no Redis instance to provision, no connection string to manage, and no backend sitting between your frontend and your data.
What Makes It Different
Puter.js inverts Redis's cost model. Instead of paying per-instance or per-hour for a running ElastiCache, MemoryDB, or Redis Cloud node — whether or not anyone is actually hitting it — Puter.js uses a User-Pays Model where each end user's reads, writes, and storage are billed to their own Puter account. For the developer, the KV layer is free to ship and free to scale: a side project with ten users and a hit app with ten million both cost the same to run.
The other piece Redis can't match is that Puter.js KV is callable directly from the browser. Redis's RESP protocol assumes a trusted backend client; exposing it to the frontend means standing up an API layer, auth, rate limiting, and per-user isolation yourself. Puter.js does that for you — data is automatically scoped per-user and per-app, so a logged-in user can persist preferences, game saves, or app state from frontend code without any server in the loop.
Key Differences from Redis
Puter.js KV is a cloud-backed key-value store, not an in-memory engine, so it won't deliver Redis's sub-millisecond latency and it doesn't try to. You also won't find Redis's rich data structures here — no lists, sorted sets, streams, pub/sub, or geospatial queries. The model is closer to DynamoDB or Cloudflare KV: simple get / set / incr / del / list operations, with relationships expressed through key naming conventions like user:42:post:001. If your workload is leaderboards, queues, or low-latency caching for a backend service, Redis is still the right tool. If it's persisting user-facing state from a web app, Puter.js removes the entire infrastructure layer.
Comparison Table
| Feature | Puter.js | Redis |
|---|---|---|
| Infrastructure | None (fully managed cloud) | Self-hosted or managed service |
| API key required | No | Yes (for managed) |
| Pricing model | User-pays (free for devs) | Per instance / per hour |
| Frontend (browser) support |  Native Native |
 (backend only) (backend only) |
| Persistence | (cloud) |
(RDB/AOF) |
| Cross-device sync | |
|
| Atomic increment/decrement | |
|
| TTL / expiration | |
|
| Rich data structures | |
Extensive |
| Pub/Sub | |
|
| Sub-millisecond latency | |
|
| Per-user data isolation | Automatic |
Manual |
| Open source | |
(AGPLv3) |
| Best for | Frontend/web app devs who want zero-cost, zero-setup storage | Backend devs needing ultra-fast in-memory ops and rich data types |
2. DynamoDB
Amazon DynamoDB is a fully managed, serverless NoSQL key-value and document database from AWS, designed for applications that need predictable performance at massive scale.
What Makes It Different
DynamoDB is built for durability and scale above all else. It automatically replicates data across multiple availability zones, handles partitioning for you, and can support over 20 million requests per second. Unlike Redis, which primarily stores data in RAM, DynamoDB persists everything to SSD-backed storage by default, making it suitable as a primary database, not just a cache.
It also supports full ACID transactions, point-in-time recovery, on-demand backups, and Global Tables for multi-region replication. For teams already in the AWS ecosystem, DynamoDB integrates tightly with Lambda, IAM, VPC endpoints, and DynamoDB Streams for change data capture.
Key Differences from Redis
DynamoDB's latency is typically in the 10–25ms range, meaningfully slower than Redis's sub-millisecond response times. To close that gap, AWS offers DynamoDB Accelerator (DAX), an in-memory cache that can boost reads by up to 10x, but it's a separate paid service. DynamoDB also lacks the rich data structures Redis provides (no sorted sets, streams, or pub/sub) and is locked to the AWS ecosystem, making it a poor fit if you're multi-cloud or building frontend-first apps. Pricing is pay-per-request or pay-per-provisioned-capacity, and costs can grow quickly under high throughput.
Comparison Table
| Feature | DynamoDB | Redis |
|---|---|---|
| Pricing model | Pay-per-request or provisioned | Per instance / per hour |
| Fully managed | |
Only on managed services |
| Primary storage | SSD (durable) | RAM (with optional disk) |
| Typical latency | 10–25 ms | Sub-millisecond |
| Persistence | Built-in |
Optional (RDB/AOF) |
| Auto-scaling | |
Manual / clustering |
| ACID transactions | |
Limited (MULTI/EXEC) |
| Rich data structures | |
Extensive |
| Pub/Sub | (use SNS/SQS) |
|
| Multi-region replication | (Global Tables) |
(Enterprise) |
| Point-in-time recovery | |
|
| In-memory caching | (via DAX, paid add-on) |
Native |
| Ecosystem lock-in | AWS only | None |
| Frontend (browser) support | |
|
| Best for | Large-scale, durable, serverless workloads on AWS | Ultra-low-latency in-memory ops and caching |
3. Valkey
Valkey is an open-source, in-memory data store forked from Redis 7.2.4, backed by the Linux Foundation and major contributors including AWS, Google Cloud, Oracle, Snap, and Ericsson.
What Makes It Different
Valkey emerged in March 2024 after Redis Inc. shifted its license away from BSD to a dual source-available model (later AGPLv3 in Redis 8). Valkey maintains the original BSD 3-Clause license, keeping it truly open source with no restrictions on commercial use, redistribution, or offering it as a managed service. It's wire-protocol compatible with Redis, so existing Redis clients and applications work without code changes.
Since the fork, Valkey has moved fast: it introduced an improved I/O multithreading model in 8.0, experimental RDMA support, per-slot cluster metrics for better observability, and in Valkey 9 it added hash field expiration, atomic slot migration, and official modules for JSON, Bloom filters, and vector search, with demonstrated benchmarks of over one billion requests per second on a 2,000-node cluster.
Key Differences from Redis
Valkey is essentially Redis without the license baggage, so the differences are subtle but important. Redis 8 has pulled ahead in some areas with natively integrated JSON, vector search, time series, and the Redis Query Engine built into the core (no modules required), while Valkey distributes these as separate bundled modules. Redis also benefits from a more mature enterprise ecosystem with commercial support from Redis Inc., while Valkey relies on community support, managed cloud providers (AWS ElastiCache/MemoryDB for Valkey, GCP Memorystore for Valkey), and third-party vendors like Percona.
Comparison Table
| Feature | Valkey | Redis |
|---|---|---|
| License | BSD 3-Clause (truly open source) | AGPLv3 / RSAL / SSPL |
| Governance | Linux Foundation (community) | Redis Inc. (commercial) |
| Wire protocol compatible | |
|
| Data structures | Same as Redis |
Extensive |
| Multi-threaded I/O | Improved |
|
| JSON support | Via module (Valkey Bundle) | Native in Redis 8 |
| Vector search | Via module | Native in Redis 8 |
| Time series | |
Native in Redis 8 |
| Full-text search | Via module | Native in Redis 8 (Query Engine) |
| Persistence (RDB/AOF) | |
|
| Clustering & replication | |
|
| RDMA support | (experimental) |
|
| Managed cloud offerings | AWS, GCP, DigitalOcean | Redis Cloud, Azure, AWS |
| Commercial support | Third-party (Percona, cloud providers) | Redis Inc. (direct) |
| Ecosystem maturity | Growing rapidly | Mature |
| Best for | Teams needing truly open-source infra without vendor lock-in | Teams needing enterprise features and direct commercial support |
4. MongoDB
MongoDB is a document-oriented NoSQL database that stores data as flexible, JSON-like BSON documents. While not a pure key-value store, it's one of the most frequently compared alternatives when teams outgrow Redis as a primary data store.
What Makes It Different
MongoDB is built around a rich document model with a proper query language, aggregation pipelines, $lookup joins, full-text search, and geospatial queries, things Redis can only approximate with manual sorted sets and scripting. Documents can be up to 16MB, support nested structures, and don't require a fixed schema, making MongoDB a better fit for complex application data that evolves over time.
MongoDB also scales horizontally via automatic sharding across regions and nodes, supports secondary indexes on any field, and has a mature ecosystem around MongoDB Atlas (its managed cloud service) with tools for analytics, search, and vector embeddings.
Key Differences from Redis
MongoDB stores data primarily on disk, which makes it significantly slower than Redis for simple key lookups, Redis delivers sub-millisecond reads while MongoDB typically responds in milliseconds. However, MongoDB uses considerably less memory for the same dataset (Redis is known to use roughly twice the RAM footprint of MongoDB in benchmarks). The two are often used together rather than as replacements: Redis in front as a cache or session store, MongoDB behind it as the persistent primary database.
Comparison Table
| Feature | MongoDB | Redis |
|---|---|---|
| Data model | Document (BSON) | Key-value + data structures |
| Primary storage | Disk (with cache) | RAM (with optional disk) |
| Typical latency | Milliseconds | Sub-millisecond |
| Memory footprint | Lower | ~2x higher for same data |
| Query language | Rich (aggregation, $lookup, etc.) |
Commands only |
| Full-text search | Built-in |
Via Redis Query Engine |
| Secondary indexes | Flexible |
Limited |
| Schema flexibility | |
N/A |
| Max value size | 16 MB (document) | 512 MB |
| Horizontal scaling | Mature sharding |
Manual / cluster |
| ACID transactions | Multi-document |
Limited (MULTI/EXEC) |
| Pub/Sub / streams | Change streams | Native |
| Persistence | Native |
Optional (RDB/AOF) |
| License | SSPL | AGPLv3 / RSAL / SSPL |
| Managed offering | MongoDB Atlas | Redis Cloud, ElastiCache, etc. |
| Best for | Primary data storage with rich queries and flexible schemas | Caching, sessions, real-time ops, and simple KV |
5. Memcached
Memcached is a high-performance, distributed in-memory key-value cache. Originally built in 2003 for LiveJournal, it's one of the longest-running open-source caching solutions still widely deployed today.
What Makes It Different
Memcached's defining trait is its minimalism. It does one thing, in-memory string caching, and it does it extremely well. Because it's multi-threaded, it scales naturally across CPU cores, often outperforming Redis by 10–15% on simple GET/SET workloads with small objects. It's fully open source under the BSD license (no licensing drama like Redis), and its slab-based memory allocator is optimized to minimize fragmentation.
Memcached is also the simplest of all the options here to deploy and reason about. There's no persistence layer to configure, no replication to tune, no data structures to model, just RAM, keys, and values.
Key Differences from Redis
Memcached is intentionally feature-poor compared to Redis. It only stores strings (or simple objects serialized as strings), has a 1MB per-value limit (vs Redis's 512MB), and supports no lists, hashes, sets, or sorted sets. It has no persistence, so all data is lost on restart, and no native replication or pub/sub. Transactions aren't supported either, though individual operations are atomic. If you need anything beyond a pure ephemeral cache, Memcached will feel limiting fast.
Comparison Table
| Feature | Memcached | Redis |
|---|---|---|
| License | BSD (fully open source) | AGPLv3 / RSAL / SSPL |
| Threading model | Multi-threaded | Single-threaded (with I/O threads in 6.0+) |
| Typical latency | Sub-millisecond | Sub-millisecond |
| Raw GET/SET speed | ~10–15% faster for small objects | Very fast |
| Max value size | 1 MB | 512 MB |
| Data structures | Strings only | Strings, lists, hashes, sets, sorted sets, streams, etc. |
| Persistence | |
(RDB/AOF) |
| Replication | Native |
|
| Clustering | Client-side consistent hashing | Redis Cluster (automatic) |
| Pub/Sub | |
|
| Transactions | |
Limited (MULTI/EXEC) |
| TTL / expiration | (LRU) |
|
| Memory efficiency | Higher (no metadata overhead) | Lower (feature overhead) |
| Operational complexity | Very low | Moderate |
| Best for | Simple, fast, ephemeral string caching | Everything beyond caching |
Which Should You Choose?
Choose Puter.js if you're building a web app and want to add a cloud key-value database without any backend, infrastructure, or running costs. The user-pays model is ideal for developers who want to ship fast without worrying about scaling or server bills.
Choose DynamoDB if you need a durable, serverless primary database on AWS that scales to millions of requests per second. It's the go-to for teams already building on AWS who need persistent storage with zero ops.
Choose Valkey if you want everything Redis offers but under a truly open-source license with community governance. It's the cleanest drop-in replacement for Redis, especially for teams that need a permissive license for commercial use.
Choose MongoDB if you've outgrown Redis as a primary data store and need a flexible document database with rich queries, secondary indexes, and horizontal scaling. It pairs well with Redis rather than replacing it outright.
Choose Memcached if you want the simplest possible in-memory cache, with nothing fancy, just fast, multi-threaded string caching. It's also a safer license bet than Redis 8 for commercially cautious teams.
Stick with Redis if you need sub-millisecond latency, rich data structures, pub/sub, streams, and a mature ecosystem, all in one engine. It remains the most versatile in-memory data store, and for many workloads, there's still no better choice.
Conclusion
The top 5 Redis alternatives are Puter.js, DynamoDB, Valkey, MongoDB, and Memcached. Each takes a different approach to the key-value database problem, from Puter.js's zero-cost, frontend-native cloud KV to DynamoDB's massive-scale serverless storage to Valkey's open-source Redis continuation. Whichever platform you choose, the best option is the one that fits your stack, your budget, and how your app actually uses data.
Related
- Getting Started with Puter.js
- Top 5 Supabase Alternatives (2026)
- Top 5 PostgreSQL Alternatives (2026)
- Top 5 PlanetScale Alternatives (2026)
- Top 5 Neon Alternatives (2026)
- Top 5 Firebase Alternatives (2026)
- Top 5 Amazon S3 Alternatives (2026)
- Top 5 DynamoDB Alternatives (2026)
- Top 5 MongoDB Alternatives (2026)
- Top 5 Memcached Alternatives (2026)
- Top 5 Turso Alternatives (2026)
Ship a Full-Stack App with One Prompt
Create a to-do list app using Puter.js
Coding manually? see the guide