Top 5 Memcached Alternatives (2026)
On this page
Memcached has been the default in-memory cache for over 20 years. It's small, multi-threaded, BSD-licensed, and proven, Facebook, Wikipedia, YouTube, and Reddit all built on it. But the design that made it dominant in 2003 also makes it limited in 2026: values are strings only, there's no persistence, no replication, no clustering, and a hard 1MB cap per value. The moment your needs grow past "fast volatile lookups," you're looking elsewhere.
This article walks through five common destinations developers move to when they outgrow Memcached, and where each one actually fits.
1. Puter.js
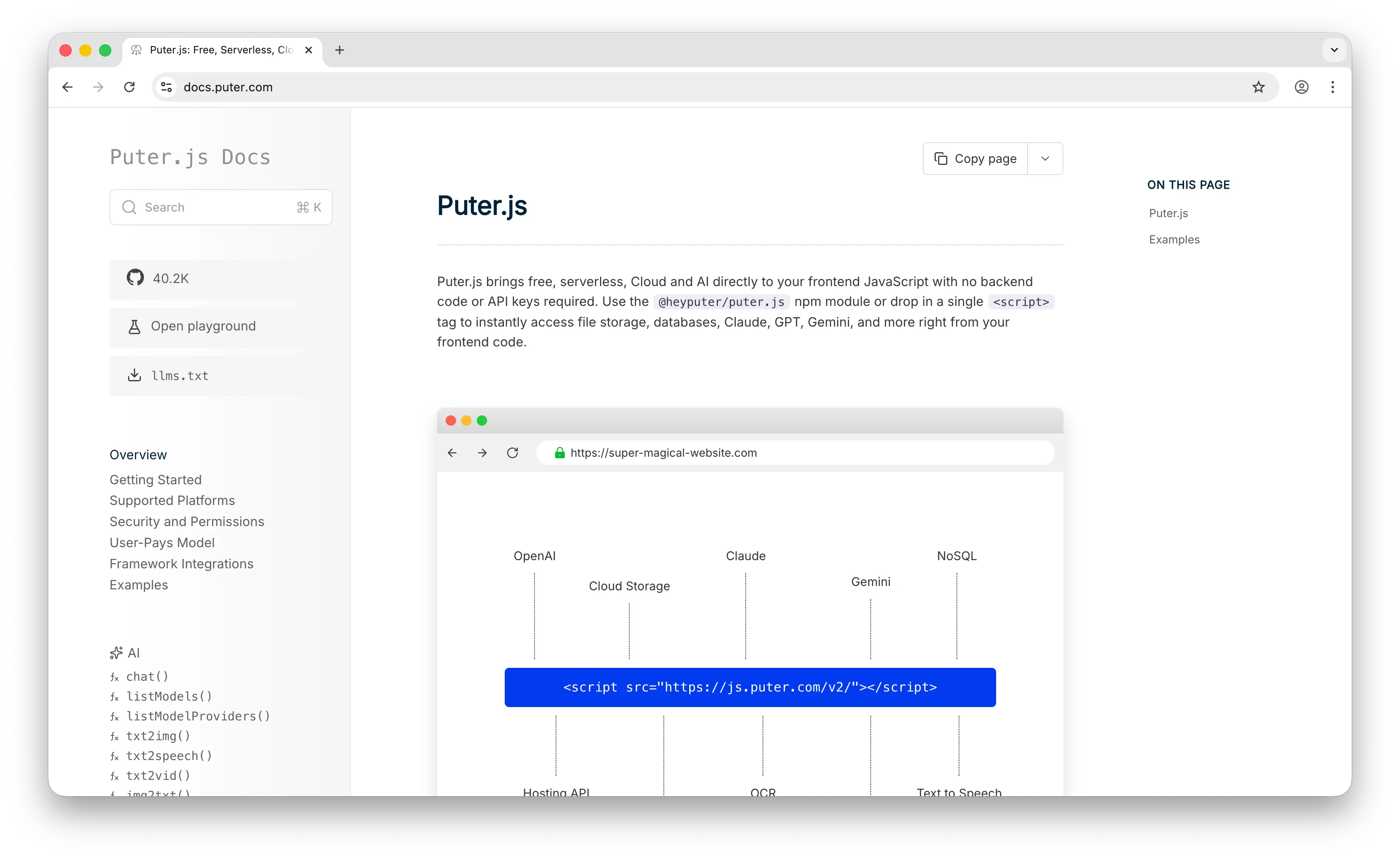
Puter.js takes a different angle from every other entry on this list. Instead of giving you a server (or a managed cluster) to point your backend at, it gives you a key-value store you call directly from the browser with a single <script> tag. There's no Memcached server to run, no client library to wire up, no port 11211 to expose. You write await puter.kv.set('key', value) from your frontend and it just works.
What Makes It Different
The model behind Puter.js is the User-Pays Model: each user of your app signs into their own Puter account, and their reads, writes, and storage are billed to them, not to you. For Memcached refugees, this is the unusual part: you're not paying for cache nodes by the hour, and you're not estimating capacity. Your app is free to deploy and scales with users automatically.
The API also covers things Memcached makes you build by hand. Values can be JSON, not just strings. Updates can target nested paths (puter.kv.update('user:42', {'stats.score': 100})) instead of read-modify-write. list() paginates with cursors. Counters increment atomically. And every key is automatically scoped per-user, per-app, so the multi-tenant isolation you'd normally implement on top of Memcached is handled for you. Data also persists, a single restart doesn't wipe state.
Key Differences from Memcached
Puter.js is a hosted service, so it's not a fit if you need to run cache nodes inside your own VPC, hit microsecond latency on a local socket, or tune slab allocators and LRU policies the way Memcached operators do. The targeted use case is also different: Memcached typically sits behind a backend API as a server-side cache, while Puter.js is designed to be called from the frontend itself, replacing the backend entirely for many app types. If your workload is "10 million ephemeral GETs per second on a fleet of bare metal servers," Memcached is still the right tool.
Comparison Table
| Feature | Puter.js | Memcached |
|---|---|---|
| Setup | Single <script> tag |
Run + manage your own servers |
| Backend required |  |
 |
| Pricing model | User-pays (free for devs) | Self-host (you pay for infra) |
| Browser-callable | |
|
| Persistence | |
|
| Data types | Strings, JSON, nested objects | Strings only |
| Partial updates by path | |
|
| Atomic counters | |
|
| Per-user data isolation | Built-in |
DIY |
| Auth handling | Built-in |
|
| Cross-device sync | |
|
| Self-hostable | |
|
| Multi-threaded | Managed for you | |
| License | Proprietary (free to use) | BSD |
| Best for | Frontend devs who want zero-cost cloud KV | Self-hosted, server-side caching at scale |
2. Redis
Redis is the in-memory data store that became the default Memcached upgrade for over a decade. It serves the same sub-millisecond key-value workloads, but adds rich data structures, persistence, replication, clustering, pub/sub, transactions, and Lua scripting on top.
What Makes It Different
Redis is a data structure server, not just a cache. Beyond strings, it natively supports lists, sets, sorted sets, hashes, streams, bitmaps, hyperloglogs, and geospatial indexes. You can implement leaderboards, rate limiters, job queues, and pub/sub messaging directly inside the store with atomic operations, instead of doing read-modify-write from your app. Redis 8 also pulled former Redis Stack modules into core, adding native JSON, time series, vector sets, and probabilistic structures (Bloom filter, Cuckoo filter, top-k, t-digest).
Redis offers two persistence mechanisms (RDB snapshots and AOF logs) and supports up to 512MB per value, well beyond Memcached's 1MB cap. Built-in primary-replica replication and Redis Cluster give you high availability and horizontal scaling without bolting on client-side sharding.
Key Differences from Memcached
The biggest change in 2025–2026 isn't technical, it's licensing. Redis 7.2.4 was the last BSD release; Redis 8.0 Community Edition is now AGPLv3, a copyleft license many organizations cannot adopt because of its network-use clause. Memcached remains BSD-licensed, which is one reason teams are sticking with it (or moving to Valkey, see below).
Redis also primarily executes commands on a single thread, while Memcached is multi-threaded and can edge it on raw GET/SET throughput on multi-core hardware. Redis uses more memory per key than Memcached (~90 bytes vs ~60 bytes of overhead) and has a heavier operational footprint to run and tune.
Comparison Table
| Feature | Redis | Memcached |
|---|---|---|
| License | AGPLv3 (CE 8.0+) | BSD |
| Data structures | Strings, lists, sets, sorted sets, hashes, streams, JSON, vectors | Strings only |
| Persistence | RDB + AOF |
|
| Max value size | 512MB | 1MB |
| Replication | Built-in |
|
| Clustering | Redis Cluster |
Client-side sharding |
| Pub/Sub | |
|
| Transactions | MULTI/EXEC |
|
| Lua scripting | |
|
| Geospatial | |
|
| Vector search | |
|
| Multi-threaded execution | (I/O threading only) |
|
| Memory overhead per key | ~90 bytes | ~60 bytes |
| Self-hostable | |
|
| Best for | Teams needing more than caching: queues, leaderboards, sessions, real-time data | Pure, simple, high-throughput key-value caching |
3. DynamoDB
DynamoDB is Amazon's fully managed NoSQL database service. It's a key-value and document store designed to scale to any size with predictable performance, and it's frequently used in places where Memcached would otherwise sit, particularly when durability matters more than microsecond latency.
What Makes It Different
DynamoDB is fully managed and serverless: there's nothing to provision, patch, or scale. You pay per request and per GB stored, and it automatically replicates data across multiple availability zones for durability. It supports point-in-time recovery, on-demand backups, IAM-based access control, encryption at rest, and global tables for multi-region replication, capabilities that don't exist in Memcached at all.
It also supports a richer document data model with nested JSON attributes, secondary indexes, conditional writes, and atomic counters. For applications already on AWS, the integration with Lambda, API Gateway, IAM, and CloudWatch is hard to beat.
Key Differences from Memcached
DynamoDB is disk-backed, not in-memory. Latency is single-digit milliseconds, not microseconds. For pure cache-the-result-of-a-query workloads, Memcached is meaningfully faster, which is why AWS itself recommends putting DAX (DynamoDB Accelerator) in front of DynamoDB for cache-tier latency, essentially adding a Memcached/Redis-style layer back in.
DynamoDB is also AWS-only, with proprietary licensing and no self-hosted equivalent. Pricing scales with usage, so high-throughput cache-style workloads (lots of small reads) can get expensive fast compared to running a few Memcached nodes.
Comparison Table
| Feature | DynamoDB | Memcached |
|---|---|---|
| Hosting | Fully managed (AWS only) | Self-host anywhere |
| Storage | Disk-backed (with optional in-memory DAX cache) | In-memory only |
| Typical latency | Single-digit ms | Sub-millisecond |
| Durability | Multi-AZ replication |
Volatile |
| Persistence | |
|
| Document model | Nested JSON |
|
| Secondary indexes | |
|
| Backups / PITR | 35-day PITR |
|
| Encryption at rest | KMS |
Limited |
| IAM access control | |
|
| Global tables (multi-region) | |
|
| Pricing model | Per-request + per-GB | Self-host infra cost |
| License | Proprietary (AWS) | BSD |
| Self-hostable | |
|
| Best for | Durable serverless KV at any scale on AWS | Pure in-memory caching, hot path latency |
4. Valkey
Valkey is the Linux Foundation–backed, BSD-licensed fork of Redis 7.2.4, created in March 2024 in direct response to Redis's license change. It's command-compatible and protocol-compatible with Redis, meaning it's a near drop-in replacement, but governed by a multi-vendor community rather than a single company.
What Makes It Different
Valkey is the license-safe Redis. It inherits all of Redis 7.2's data structures, persistence, replication, and clustering, then continues development under BSD with contributions from AWS, Google Cloud, Oracle, Ericsson, and 300+ other contributors. AWS ElastiCache now defaults to Valkey as its Redis-compatible engine, and Google Cloud Memorystore added Valkey support in early 2026.
The project has also moved beyond just keeping the lights on. Valkey 8.0 introduced I/O multi-threading, Valkey 8.1 brought significant performance improvements and a new hash table design with up to 40% lower memory usage, and Valkey 9 added official BSD-licensed modules for JSON, Bloom filters, and vector search, all bundled in the Valkey Bundle.
Key Differences from Memcached
Valkey carries the same trade-offs as Redis vs Memcached: more features, more memory overhead, more operational complexity, and primarily single-threaded command execution (though I/O threading helps). If you only need string-keyed GET/SET at maximum throughput on a multi-core box, Memcached's pure multi-threaded design is still simpler and lighter.
What you get for that complexity is everything Memcached doesn't have: persistence, replication, clusters with automatic failover, pub/sub, transactions, scripting, and a rich data type library, all under a permissive license.
Comparison Table
| Feature | Valkey | Memcached |
|---|---|---|
| License | BSD 3-clause | BSD |
| Governance | Linux Foundation, multi-vendor | Community |
| Redis command compatibility | Drop-in for Redis 7.2 |
|
| Data structures | Strings, lists, sets, sorted sets, hashes, streams, + JSON/vectors via modules | Strings only |
| Persistence | RDB + AOF |
|
| Max value size | 512MB | 1MB |
| Replication | Built-in |
|
| Clustering | Up to 2,000 nodes |
Client-side sharding |
| Pub/Sub | |
|
| Transactions | |
|
| I/O multi-threading | Since 8.0 |
Native |
| Vector search / Bloom filters | Official modules |
|
| Per-slot cluster metrics | |
|
| Default in AWS ElastiCache | |
Separate engine |
| Self-hostable | |
|
| Best for | Teams that want Redis features under a permissive license | Pure, simple, multi-threaded caching |
5. MongoDB
MongoDB is a document database that's sometimes proposed as a Memcached alternative, particularly by teams who realize their real bottleneck wasn't caching at all, it was needing to query nested data without joins.
What Makes It Different
MongoDB is a flexible document store, not a cache. It stores BSON documents with arbitrary nesting, supports a rich query language (MQL) with aggregation pipelines, secondary indexes on any field, multi-document ACID transactions, and full-text search. Its WiredTiger storage engine keeps a working set in RAM (typically 50% of system memory) and persists everything to disk for durability.
For workloads that need both fast lookups and the ability to query, filter, and aggregate, MongoDB can replace the database-plus-cache pattern entirely. Replica sets give you automatic failover, sharding gives you horizontal scaling, and MongoDB Atlas handles the operations side as a managed service.
Key Differences from Memcached
MongoDB is honestly a different category of tool. Read latency is typically 1–10ms for indexed queries, an order of magnitude slower than Memcached's sub-millisecond performance. Memory and storage footprint are much larger, and write throughput per node is lower. For pure cache-the-result-of-a-database-query workloads, MongoDB is the wrong choice.
In practice, many teams run MongoDB and Memcached together: Mongo as the source of truth, Memcached in front for hot reads. So this entry is less "swap Memcached for MongoDB" and more "you may not need Memcached if MongoDB's WiredTiger cache plus indexes already give you the response times you want."
Comparison Table
| Feature | MongoDB | Memcached |
|---|---|---|
| Category | Document database | In-memory cache |
| Storage | Disk-backed (WiredTiger cache in RAM) | In-memory only |
| Typical read latency | 1–10ms (indexed) | Sub-millisecond |
| Data model | BSON documents, nested fields | Strings (KV) |
| Query language | MQL + aggregation pipelines | GET/SET only |
| Indexes | Any field |
|
| Persistence | Durable to disk |
|
| Replication | Replica sets |
|
| Sharding | Built-in |
Client-side |
| Multi-document transactions | ACID |
|
| Full-text search | |
|
| Schema | Flexible | N/A |
| License | SSPL (community) / commercial | BSD |
| Managed offering | MongoDB Atlas | Various (ElastiCache, etc.) |
| Best for | Querying, aggregating, and persisting nested data | Pure key-value caching at low latency |
Which Should You Choose?
Choose Puter.js if you're building a web app and want a persistent key-value store without running any backend or paying any infrastructure costs. The user-pays model is ideal for frontend developers who don't want to deal with servers, billing, or scaling, and need cross-device persistence that Memcached can't offer.
Choose Redis if you've outgrown plain caching and need data structures, persistence, pub/sub, or clustering, and the AGPLv3 license is acceptable for your organization. It's still the most feature-rich option in the in-memory data store space.
Choose DynamoDB if you're already on AWS, need a durable serverless key-value store, and care more about not losing data and not running servers than about microsecond latency. Pair with DAX if you do need cache-tier speeds.
Choose Valkey if you want everything Redis offers but under a permissive BSD license and multi-vendor governance. It's the safer long-term bet for organizations that can't take on AGPLv3, and it's already the default Redis-compatible engine on AWS ElastiCache.
Choose MongoDB if your real problem isn't caching, it's that you need to query and aggregate nested data with persistence, indexes, and durability. Don't pick it as a Memcached replacement; pick it because you're consolidating a database-plus-cache stack into one tool.
Stick with Memcached if you need pure, multi-threaded, in-memory key-value caching at maximum throughput, your data is genuinely ephemeral, and you have the ops capability to run it. For simple cache-aside patterns at scale, it's still excellent and BSD-licensed.
Conclusion
The top 5 Memcached alternatives are Puter.js, Redis, DynamoDB, Valkey, and MongoDB. Each takes a different approach to going beyond Memcached's deliberately minimal design, from Puter.js's zero-backend cloud KV for frontend developers, to Redis's data-structure-server model, to DynamoDB's managed durability, to Valkey's BSD-licensed Redis fork, to MongoDB's document database. Whichever platform you choose, the best option is the one that fits your stack, your latency budget, and how durable your data actually needs to be.
Related
- Getting Started with Puter.js
- How to Use Puter.js Key-Value Store API
- Top 5 Redis Alternatives (2026)
- Top 5 PostgreSQL Alternatives (2026)
- Top 5 PlanetScale Alternatives (2026)
- Top 5 Neon Alternatives (2026)
- Top 5 DynamoDB Alternatives (2026)
- Top 5 MongoDB Alternatives (2026)
- Top 5 Upstash Alternatives (2026)
- Top 5 Turso Alternatives (2026)
Ship a Full-Stack App with One Prompt
Create a to-do list app using Puter.js
Coding manually? see the guide