Best fal.ai Alternatives (2026)
On this page
fal.ai is a generative media inference platform built for speed. It runs over 1,000 models for image, video, audio, and 3D generation on serverless GPU infrastructure with custom CUDA kernels. It's known for fast inference, output-based pricing, and a focus on media generation workloads.
But fal.ai isn't the only option. Depending on your use case, there are alternatives that may offer broader model access, lower costs, or features that fal.ai doesn't support.
In this article, you'll learn about five fal.ai alternatives, how they compare, and which one might be the best fit for your project.
1. Puter.js
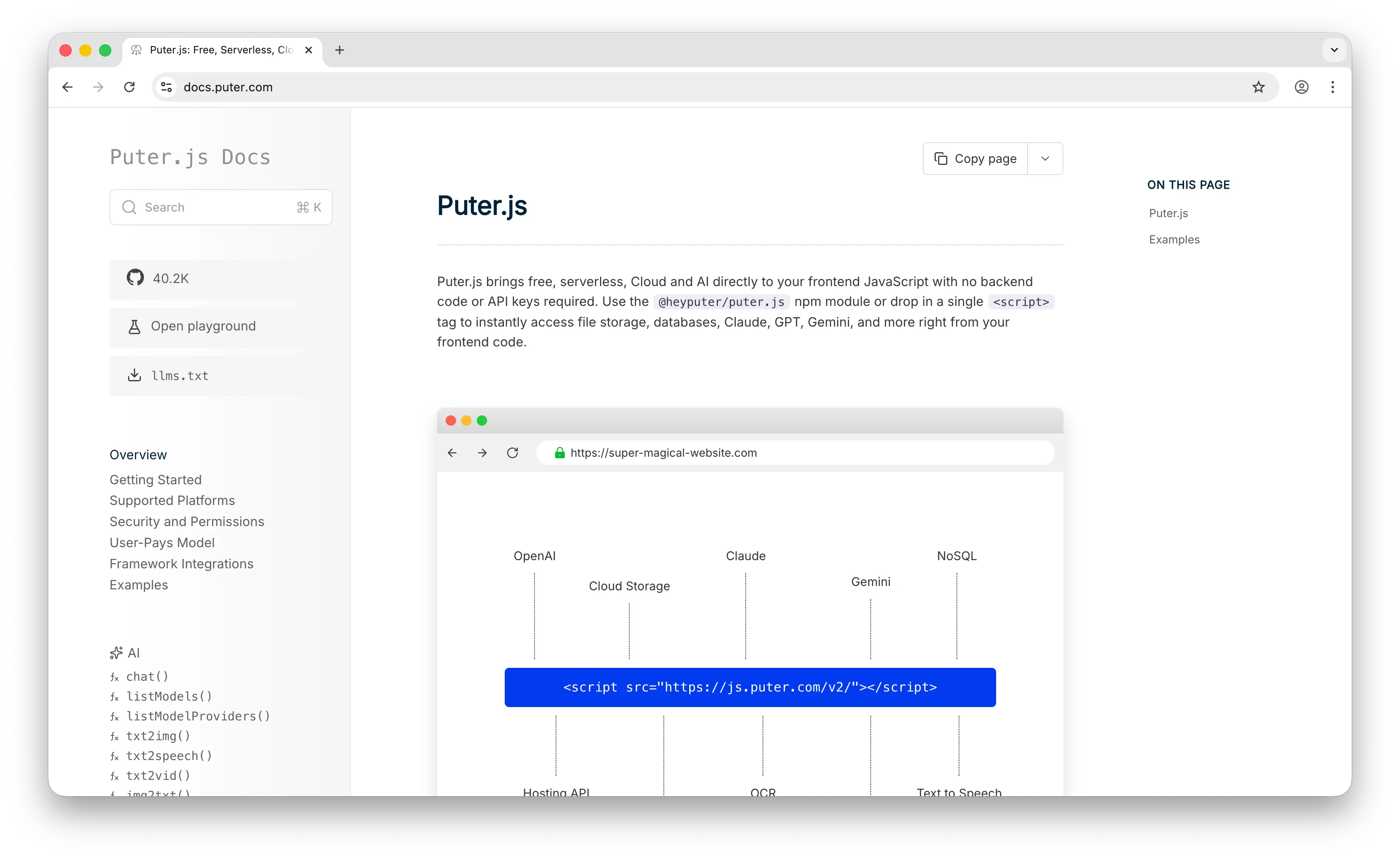
Puter.js is a JavaScript library that bundles AI, database, cloud storage, authentication, and more into a single package. It supports over 400 models from providers like OpenAI, Anthropic, Google, Meta, and others, spanning chat, image generation, video generation, text-to-speech, and speech-to-text.
What Makes It Different
Puter.js pioneered the User-Pays Model: your app users cover their own AI usage costs through their Puter account. Developers pay nothing for AI inference — no API key, no backend, no server-side setup required. This is fundamentally different from fal.ai, where the developer is billed for every image, video, or audio generation.
Puter.js also goes beyond what fal.ai offers in terms of built-in services. Alongside AI, you get cloud storage, a key-value database, and user authentication — all from a single library. For web app developers, this eliminates the need to piece together separate services.
Key Differences from fal.ai
Puter.js is primarily designed for web apps running on the frontend. While it works in Node.js, the user-pays model is most natural in a browser context. Unlike fal.ai, Puter.js does not offer custom CUDA kernel optimizations, dedicated GPU compute, fine-tuning, or custom model deployment. Its model catalog (400+) is curated from major providers, while fal.ai's 1,000+ endpoints are focused on media generation with highly optimized inference.
fal.ai's strength is raw speed and cost-efficiency for media generation. Puter.js's strength is eliminating developer costs entirely and bundling multiple services into one library.
Comparison Table
| Feature | Puter.js | fal.ai |
|---|---|---|
| Pricing model | User-pays (free for devs) | Per-output (per image/video second) |
| Free tier |  (free for developers) (free for developers) |
Promotional credits only |
| API key required | No | Yes |
| Chat/LLM models | Extensive (380+) |
Limited (proxied via OpenRouter) |
| Image generation | |
Excellent |
| Video generation | |
Excellent |
| Audio (TTS/STT) | |
|
| 3D generation |  |
|
| Embeddings | |
|
| Fine-tuning | |
(LoRA) |
| Custom model deployment | |
(Serverless, Deploy, Compute) |
| Dedicated GPU compute | |
(with SSH access) |
| Inference speed | Standard | Up to 4x faster (custom CUDA kernels) |
| Built-in services (DB, storage, auth) | |
|
| Open-source models | |
|
| Closed-source models | |
(Kling, Hailuo, Veo) |
| Queue system with webhooks | |
(built-in, priority tiers) |
| Best for | Web app devs who want zero-cost AI integration | Fast, optimized media generation at scale |
2. Replicate
Replicate is a pay-as-you-go platform for running AI models via API. It hosts over 50,000 models, charges developers based on compute time, and lets anyone publish models using its open-source packaging tool, Cog. It was acquired by Cloudflare in November 2025.
What Makes It Different
Replicate has the largest community model ecosystem in the industry. Its 50,000+ Cog-packaged models dwarf fal.ai's 1,000+ curated endpoints. If you need a niche model — a specific fine-tuned Stable Diffusion variant, a research model, or a community-published custom pipeline — Replicate is far more likely to have it.
Replicate also offers broader model coverage beyond media. It supports LLMs, embeddings, and a wider variety of model types, while fal.ai proxies its LLM requests through OpenRouter rather than hosting them natively.
With the Cloudflare acquisition, Replicate's models are increasingly running on Cloudflare's global edge network, which may improve latency and integration with Cloudflare's ecosystem (Workers, R2, Vectorize).
Key Differences from fal.ai
fal.ai is faster and often cheaper for mainstream media generation models. Its custom CUDA kernels and optimized infrastructure deliver faster inference with near-zero cold starts on warm models. For the same popular models (Flux, Kling, Wan), fal.ai can be 30–50% cheaper with more predictable output-based pricing, while Replicate charges per-second of compute time.
Replicate's per-second pricing means costs vary based on how long a GPU takes to process your request, which can be unpredictable. fal.ai's per-output pricing (e.g., $0.025 per image, $0.05–$0.40 per video second) tells you exactly what you'll pay upfront.
However, Replicate's community ecosystem and broader model type support make it more versatile for projects that need more than just media generation.
Comparison Table
| Feature | Replicate | fal.ai |
|---|---|---|
| Pricing model | Per-second compute time | Per-output (per image/video second) |
| Free tier | |
Promotional credits only |
| Model catalog | 50,000+ (community Cog models) | 1,000+ (curated endpoints) |
| Chat/LLM models | Growing |
Limited (proxied via OpenRouter) |
| Image generation | Excellent |
Excellent |
| Video generation | Excellent |
Excellent |
| Audio models | |
|
| 3D generation | Limited | |
| Embeddings | |
|
| Open-source models | Extensive |
|
| Closed-source models | (GPT, Claude, Gemini) |
(Kling, Hailuo, Veo) |
| Community model publishing | (via Cog) |
|
| Fine-tuning | |
(LoRA) |
| Custom model deployment | (via Cog) |
(Serverless, Deploy, Compute) |
| Dedicated GPU compute | |
(with SSH access) |
| Inference speed | Standard | Up to 4x faster (custom CUDA kernels) |
| Cold start latency | Can be slow on less-popular models | Near-zero on warm models |
| Queue system with webhooks | (async predictions) |
(built-in, priority tiers) |
| Edge deployment | (via Cloudflare) |
|
| Best for | Broad model ecosystem, community models, LLMs + media | Fast, cost-effective media generation at scale |
3. OpenRouter
OpenRouter is a unified API gateway that provides access to 300+ models from 60+ providers through a single API key. It handles routing, fallback, and billing across providers like OpenAI, Anthropic, Google, Meta, and others.
What Makes It Different
OpenRouter excels where fal.ai is weakest: LLMs and chat models. fal.ai doesn't host LLMs natively — it actually proxies LLM requests through OpenRouter. If your application needs both media generation and strong LLM capabilities, you'd need fal.ai plus another service for LLMs. OpenRouter covers the LLM side comprehensively with 300+ models, including both open-source and closed-source options.
OpenRouter's API is fully OpenAI-compatible, making it a drop-in replacement for any app using the OpenAI SDK. It offers automatic fallback when providers go down, provider preferences by cost or speed, and variant suffixes (:free, :nitro, :floor) for fine-grained routing control.
Key Differences from fal.ai
OpenRouter is not an infrastructure platform. It doesn't host models on its own GPUs, offer fine-tuning, provide dedicated compute, or support custom model deployment. It's a routing layer.
For media generation, OpenRouter has limited support: image generation is available, video is experimental, and audio is not supported. This is the opposite of fal.ai, which is purpose-built for media generation with optimized inference speeds and a deep catalog of image, video, audio, and 3D models.
Pricing also differs: OpenRouter charges a 5.5% fee on credit purchases and passes through provider pricing at cost. fal.ai charges per-output with pricing that varies by model.
Comparison Table
| Feature | OpenRouter | fal.ai |
|---|---|---|
| Pricing model | Pay-as-you-go (5.5% credit fee) | Per-output (per image/video second) |
| Free tier | (free models with rate limits) |
Promotional credits only |
| Chat/LLM models | Extensive (300+) |
Limited (proxied via OpenRouter) |
| Image generation | |
Excellent |
| Video generation | Experimental | Excellent |
| Audio models | |
|
| 3D generation | |
|
| Embeddings | |
|
| Open-source models | |
|
| Closed-source models | Extensive |
(Kling, Hailuo, Veo) |
| Fine-tuning | |
(LoRA) |
| Custom model deployment | |
(Serverless, Deploy, Compute) |
| Dedicated GPU compute | |
(with SSH access) |
| Inference speed | Depends on provider | Up to 4x faster (custom CUDA kernels) |
| Fallback/routing | (automatic) |
|
| OpenAI-compatible API | |
(proprietary, except LLM proxy) |
| Best for | Broad LLM access with multi-provider routing | Fast, optimized media generation at scale |
4. Hugging Face Endpoints
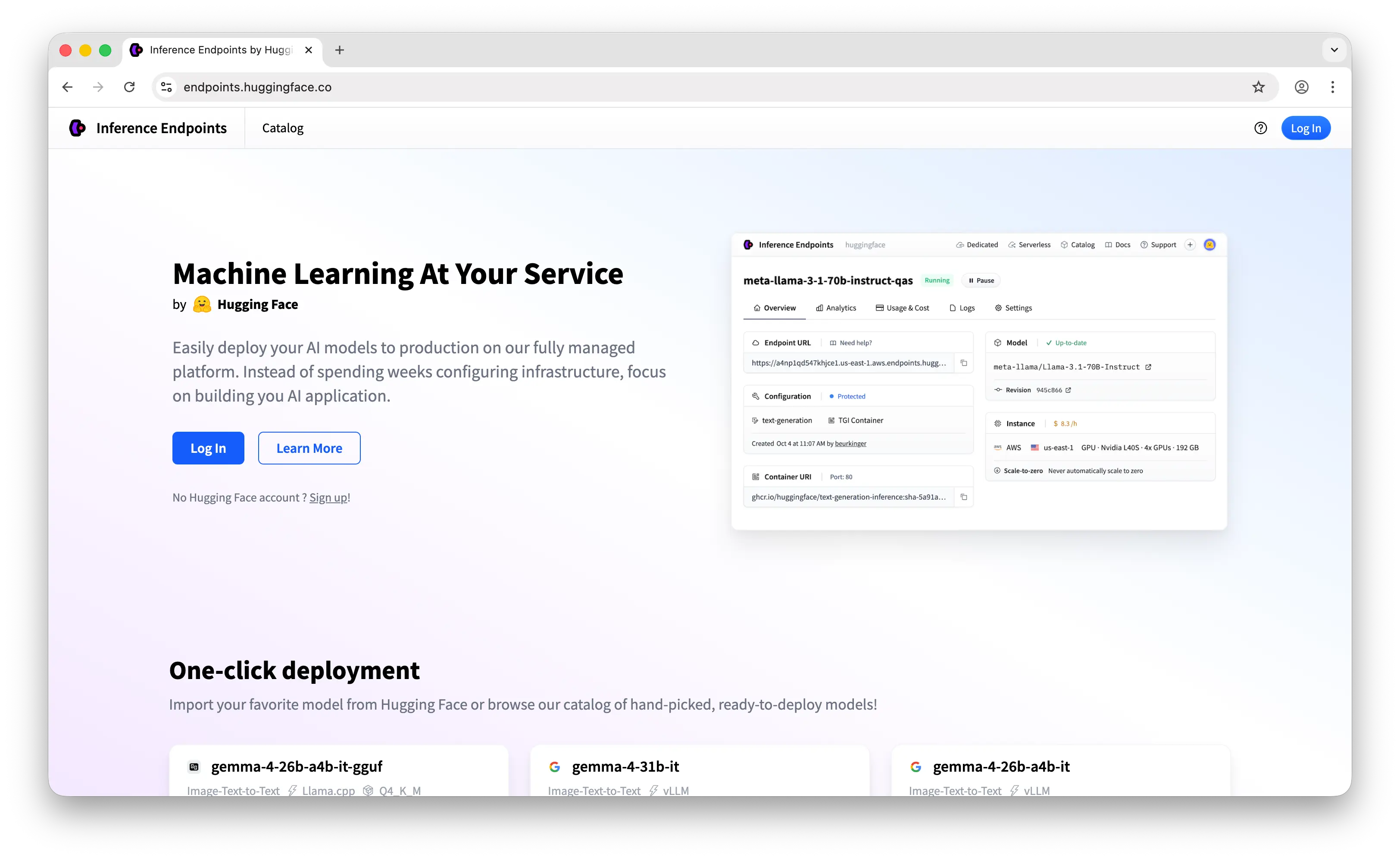
Hugging Face Inference Endpoints is a service for deploying any model from the Hugging Face Hub on dedicated, fully managed infrastructure. You pick a model from the Hub's 2 million+ catalog, choose your GPU hardware, and get a production-ready API endpoint with autoscaling, scale-to-zero, and private networking.
What Makes It Different
Inference Endpoints gives you dedicated infrastructure and access to the largest model catalog available anywhere. Any of the Hub's 2 million+ models — including niche fine-tuned variants, research models, and your own private uploads — can be deployed as an endpoint. fal.ai's 1,000+ curated endpoints can't match this breadth.
The platform also supports model types that fal.ai doesn't: embeddings (via TEI), reranking models, and a full range of NLP tasks. You get OpenAI-compatible APIs, custom containers (TGI, TEI, Diffusers, or your own Docker image), and private networking via AWS/Azure PrivateLink.
For teams that need full control over their inference infrastructure — hardware selection, autoscaling policies, private networking, and the ability to deploy any model — Hugging Face Inference Endpoints offers significantly more flexibility than fal.ai's serverless approach.
Key Differences from fal.ai
Inference Endpoints charges per-minute of uptime for dedicated hardware, starting at ~$0.03/hr for CPU and ~$0.50/hr for GPU. This is more expensive for sporadic workloads compared to fal.ai's per-output pricing, but more cost-effective for sustained, high-throughput workloads where you can keep hardware utilized.
fal.ai is faster for media generation thanks to its custom CUDA kernel optimizations, which Hugging Face doesn't offer. For latency-sensitive media generation, fal.ai has a clear edge. However, Hugging Face's scale-to-zero feature and autoscaling make it better for workloads with variable traffic patterns.
Inference Endpoints does not have a curated marketplace or pre-optimized media generation pipeline. You're deploying raw models and managing the inference stack, which gives more control but requires more setup.
Comparison Table
| Feature | HF Inference Endpoints | fal.ai |
|---|---|---|
| Pricing model | Per-minute uptime (dedicated hardware) | Per-output (per image/video second) |
| Free tier | (free CPU endpoints) |
Promotional credits only |
| Deployable models | 2,000,000+ (any Hub model) | 1,000+ (curated endpoints) |
| Chat/LLM models | Extensive (via TGI) |
Limited (proxied via OpenRouter) |
| Image generation | (via Diffusers) |
Excellent |
| Video generation | (via Diffusers) |
Excellent |
| Audio models | |
|
| 3D generation | (deploy any model) |
|
| Embeddings | (via TEI) |
|
| Dedicated hardware | (GPU selection, autoscaling) |
(fal Compute, SSH access) |
| Scale-to-zero | |
(serverless) |
| Custom containers | (TGI, TEI, Diffusers, Docker) |
(fal Serverless) |
| Private networking | (AWS/Azure PrivateLink) |
Limited |
| Fine-tuning | (AutoTrain, LoRA, QLoRA, DPO) |
(LoRA) |
| Community model publishing | (Hub uploads) |
|
| Inference speed | Standard (no custom kernels) | Up to 4x faster (custom CUDA kernels) |
| OpenAI-compatible API | |
(proprietary, except LLM proxy) |
| Best for | Dedicated deployment of any model with full infra control | Fast, optimized media generation at scale |
5. Together AI
Together AI is a full-stack AI inference and training platform focused on open-source models. It provides serverless inference, dedicated GPU endpoints, batch processing, and fine-tuning — all backed by research-driven optimizations like FlashAttention.
What Makes It Different
Together AI is AI infrastructure with a strong focus on LLMs and open-source models. It offers dedicated GPU endpoints with guaranteed throughput, GPU clusters (H100/H200) you can provision in minutes, and batch inference at a 50% discount. These are infrastructure capabilities that go beyond what fal.ai offers for text-based workloads.
Its API is OpenAI-compatible, and it supports a wide range of model types: chat, image generation, audio, vision, embeddings, reranking, and code. Together AI also has stronger LLM inference than fal.ai, which doesn't host LLMs natively.
Together AI offers $25 in free credits for new users, compared to fal.ai's promotional credit system.
Key Differences from fal.ai
Together AI's media generation capabilities are more limited than fal.ai's. Its video generation support is minimal, it doesn't offer 3D generation, and its image generation catalog is smaller. fal.ai's custom CUDA kernels and output-based pricing give it a clear advantage for media-heavy workloads.
Together AI focuses almost exclusively on open-source models — no closed-source models like GPT or Claude. fal.ai offers closed-source media models like Kling, Hailuo, and Veo alongside open-source options.
Pricing differs: Together AI charges per-token for serverless text inference and per-GPU-hour for dedicated endpoints. fal.ai charges per-output for media generation. Per-token pricing is more predictable for text workloads, while per-output pricing is more predictable for media.
Comparison Table
| Feature | Together AI | fal.ai |
|---|---|---|
| Pricing model | Per-token (serverless) / per-GPU-hour (dedicated) | Per-output (per image/video second) |
| Free tier | ($25 credit) |
Promotional credits only |
| Chat/LLM models | Extensive (200+) |
Limited (proxied via OpenRouter) |
| Image generation | |
Excellent |
| Video generation | Limited | Excellent |
| Audio models | |
|
| 3D generation | |
|
| Embeddings | |
|
| Reranking models | |
|
| Open-source models | Extensive (200+) |
|
| Closed-source models | |
(Kling, Hailuo, Veo) |
| Fine-tuning | (full + LoRA) |
(LoRA) |
| Custom model deployment | Upload from Hugging Face | (Serverless, Deploy, Compute) |
| Dedicated endpoints | |
(fal Compute) |
| GPU clusters | (H100/H200) |
(A100/H100/H200/B200) |
| Batch inference | (50% discount) |
|
| Inference speed | Fast (FlashAttention) | Up to 4x faster for media (custom CUDA kernels) |
| OpenAI-compatible API | |
(proprietary, except LLM proxy) |
| Best for | LLM inference, fine-tuning, and GPU infra at scale | Fast, optimized media generation at scale |
Which Should You Choose?
Choose Puter.js if you're building a web app and want to add AI features without any API costs or backend setup. The user-pays model means your users cover their own usage, making it ideal for developers and startups that don't want to worry about scaling inference costs.
Choose Replicate if you need the largest community model ecosystem (50,000+ Cog models), want a single platform that handles both LLMs and media generation, or rely on niche community-published models. Its Cloudflare integration is also improving edge performance over time.
Choose OpenRouter if your primary need is LLM access across many providers with automatic fallback and routing. It's the simplest option for teams that want broad model coverage through a single, OpenAI-compatible endpoint.
Choose Hugging Face Inference Endpoints if you need dedicated, autoscaling infrastructure for deploying any model with full control over hardware, private networking, and the ability to tap into 2 million+ models on the Hugging Face Hub.
Choose Together AI if you need fast open-source LLM inference, batch workloads at a discount, fine-tuning capabilities, or dedicated GPU infrastructure with guaranteed throughput.
Stick with fal.ai if media generation (images, video, audio, 3D) is your primary workload and speed matters. Its output-based pricing, near-zero cold starts, and custom CUDA optimizations make it the fastest and most cost-effective option for generative media at scale.
Conclusion
The best fal.ai alternatives are Puter.js, Replicate, OpenRouter, Hugging Face Inference Endpoints, and Together AI. Each takes a different approach: Puter.js eliminates developer costs entirely, Replicate offers the largest community model ecosystem, OpenRouter provides the broadest LLM routing, Hugging Face Inference Endpoints gives you dedicated deployment with full infrastructure control, and Together AI delivers fast open-source LLM inference with GPU infrastructure. The best choice depends on your workload — whether that's web app AI, broad model access, LLM inference, dedicated model deployment, or media generation.
Related
Free, Serverless AI and Cloud
Start creating powerful web applications with Puter.js in seconds!
Get Started Now