The Best Backend Platform for Vibe Coding
Choosing the backend platform you use is one of the most important decisions when vibe coding, because it shapes what your app can do, how often the AI hallucinates during agentic coding, and how badly things break in production. And it's not as simple as picking the most popular one. There are a handful of criteria that decide whether a platform is actually good for vibe coding or just looks good on a landing page.
In this article you'll learn what those criteria are, and which platforms hold up the best against them.
The Criteria
For a framework, SDK, or platform to be good at vibe coding, we find it must follow these:
- Training-data density: how much of the platform the model has seen, which determines hallucination rate.
- API stability: whether the platform avoids breaking changes that cause the AI to mix old and new idioms.
- Opinionated conventions: one obvious way to do things, so fewer forks for the AI to pick wrong.
- Safe defaults: auth, CSRF, SQL injection, and secrets handled by the platform so vibe-coded apps don't ship vulnerabilities.
- Type safety: a strict compiler that catches the AI's small mistakes before runtime.
- Batteries included: ORM, auth, jobs, email, etc. in one box, so no fragile glue code between fifteen libraries.
- Fast feedback loop: hot reload, instant errors, one-command run and deploy, so the prompt-look-reprompt cycle stays tight.
- Self-contained project: a single repo the model can hold in its head, not a microservices mesh.
- Test ergonomics: trivial to generate and run tests as a safety net for code you didn't read.
- Observability built-in: logging and error reporting by default, so production failures are visible to someone who doesn't fully understand the code.
These all influence how easy it is to vibe code, and how often you'll find yourself going in circles trying to fix something the AI made up.
Puter.js
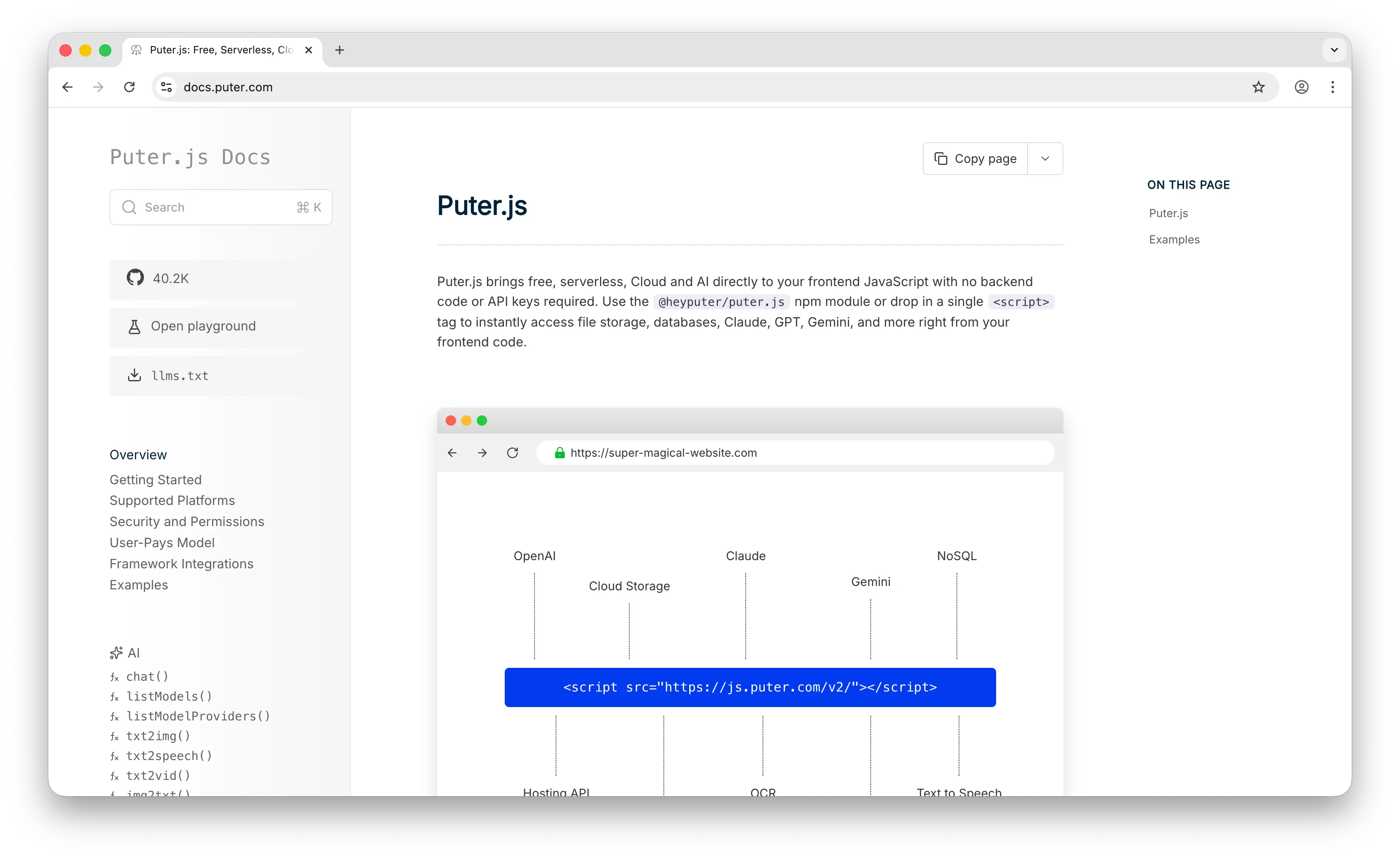
Puter.js is the newest of the three, so the training-data density is still growing. That said, more and more projects on GitHub are using it, and models are getting better at it fast.
API stability is solid in practice. The CDN pins everyone to v2 via the /v2/ path, and v2 has been stable for years, so old tutorials and old code still work. There was a v1 before, but it's so far in the past that you're unlikely to hit it.
Opinionated conventions are one of Puter.js's quiet strengths. There's a consistent format for AI calls regardless of which model you're hitting:
<script src="https://js.puter.com/v2/"></script>
<script>
puter.ai.chat("write a haiku about cats", { model: "gpt-5.4-nano" })
.then(puter.print);
</script>
The same shape works for OpenAI, Claude, Gemini, Grok, DeepSeek, and Kimi. In the regular world each of these providers has a completely different SDK, different auth, and different request shape. Puter.js collapses all of that into one call. Same story for storage (puter.fs.*), key-value (puter.kv.*), and hosting (puter.hosting.*).
Safe defaults: you're protected from common attacks like CSRF and SQL injection because you're not managing a server. Each database and storage namespace is isolated per user. Auth is included and handled automatically — when your code tries to access cloud services, Puter prompts the user to sign in. There are also no API keys to leak, because the User-Pays Model means auth is per-user, not per-app.
Type safety: Puter.js ships .d.ts type definitions via its npm package, so you get autocomplete and type checking on the puter.* APIs out of the box when using TypeScript.
Batteries included is where Puter.js really shines. Database, auth, storage, hosting, AI (every major model), and serverless workers, all in a single library. You don't stitch anything together. A "hello world" that uses AI, saves data, and hosts a page looks like this:
<script src="https://js.puter.com/v2/"></script>
<script>
(async () => {
// Store a value
await puter.kv.set("greeting", "hello world");
// Ask an LLM
const reply = await puter.ai.chat("say hi");
// Host a page on a random subdomain
const dir = puter.randName();
await puter.fs.mkdir(dir);
await puter.fs.write(`${dir}/index.html`, `<h1>${reply}</h1>`);
const site = await puter.hosting.create(puter.randName(), dir);
puter.print(`live at https://${site.subdomain}.puter.site`);
})();
</script>
The feedback loop is as tight as it gets. You don't set up infrastructure, you don't manage API keys, you don't deploy a backend. A single HTML file with a script tag is a working app. Refresh and you're testing.
Self-contained: a single repo or even a single HTML file holds your entire application.
Test ergonomics are decent. There's a testMode: true flag on AI calls so you can test code without burning credits, which is nice. Beyond that you use whatever JS test tooling you want (Vitest, Playwright) since everything runs in the browser.
Observability is the weakest area. Since it's client-only, traditional backend APM and server logs don't apply, so you'd bolt on something like Sentry for client-side errors. The docs also don't clearly specify rate limits or usage quotas, which means you can hit unexpected behavior in production. It's the tradeoff for the simplicity everywhere else.
A few extra things worth knowing about Puter.js that don't fit neatly into the criteria but matter for vibe coding:
- The User-Pays Model is a vibe-coding feature With most platforms you have to wire up billing, set rate limits, and worry about a viral user nuking your free tier. With Puter.js the developer pays $0 regardless of user count, because each user covers their own usage out of their own Puter credits. One less thing for you (and the AI) to get wrong.
- No API keys is bigger than it sounds. Every other backend has the same routine — put keys in
.env, don't commit them, set up proxies so they don't leak to the client, rotate them when one is exposed. With Puter.js there's literally nothing to leak. For vibe coding specifically, this removes one of the most common ways AI-generated code ships vulnerabilities (hardcoded keys in client bundles). - It's open source and self-hostable (AGPL-3.0), which Firebase isn't; Supabase is too. Matters if you care about long-term lock-in.
- The honest limitations: no scheduled jobs, no traditional background workers, and everything has to happen in response to user actions in the browser. You can't run cron tasks or process things server-side without users present. The newer serverless workers feature closes some of this gap but not all of it. Puter.js is great for apps where the user does something and the app responds; worse for apps that need to do things on their own.
Firebase
Firebase is the oldest player in this space, owned by Google, so the training-data density is massive. Basically every model has seen large amounts of Firebase code, and hallucinations on core stuff like Firestore and auth are rare.
API stability is its biggest weakness for vibe coding though. Firebase went through a major v8 to v9 migration where they moved from the namespaced API to a modular tree-shakeable one. The two styles look completely different:
// v8 (old, namespaced)
firebase.firestore().collection("users").doc("123").get();
// v9 (modular, current)
import { doc, getDoc, getFirestore } from "firebase/firestore";
const db = getFirestore();
await getDoc(doc(db, "users", "123"));
AI models frequently mix these in the same file, which breaks things in subtle ways. Firebase does ship a compat layer so old code still works, but you have to keep an eye on which version your code is actually using. If you start fresh and force the AI to stay on the modular API consistently, it works great — just don't let it drift.
Opinionated conventions are strong. Firestore has one obvious way to structure queries, auth has one obvious flow, and the docs reinforce these patterns.
Safe defaults: Firebase has security rules, a domain-specific language for controlling access to Firestore, Storage, and the Realtime Database. By default everything is locked down. If you don't write rules, your data is inaccessible, which is the safe failure mode.
Type safety: the JS SDK has first-class TypeScript support out of the box, but Firestore documents are loosely typed by default since it's a NoSQL store. You can layer your own types on top, but the database itself won't enforce them. So types help the AI write correct call sites, not correct schemas.
Batteries included is extensive: auth, Firestore, Realtime Database, Cloud Functions, Cloud Storage, hosting, push notifications (FCM), analytics, Remote Config, Crashlytics, A/B testing. All in one console, all one SDK.
Fast feedback loop is excellent. The Firebase Emulator Suite lets you run the entire stack locally, hot reload included. One command to deploy.
Self-contained: yes, one project, one config, one SDK.
Test ergonomics are pretty good. The emulator suite is designed for testing and you can wipe state between runs. Mocking Firestore is well-trodden territory with lots of libraries.
Observability is great on mobile, weaker on web. Crashlytics is the gold standard for iOS and Android crash reporting. For web it's still being built out — the Firebase team is currently soliciting feedback on what web Crashlytics should look like. Cloud Logging integration exists for the server-side stuff.
Supabase
Supabase is younger than Firebase, but training-data density is already huge because it's marketed everywhere as "the open-source Firebase alternative," and basically every tutorial in the last few years uses it. Models handle it reliably.
API stability has been good since v2 of supabase-js. The PostgREST-based API is the same one it shipped with, the auth client has been stable, and edge functions have evolved in a mostly additive way. No big v8-to-v9 style rewrite.
Opinionated conventions: it pushes you hard toward Postgres, row-level security for authorization, and PostgREST for auto-generated REST endpoints. There's basically one way to do each thing.
Safe defaults: row-level security (RLS) is the headline feature here. You enable RLS on a table and define policies in SQL, and the database itself enforces them on every query. It's the same defense-in-depth model Firebase uses, but at the database layer where it's harder to bypass. SQL injection is also handled by the client library since you're not writing raw queries.
Type safety is Supabase's biggest win over the other two. The Supabase CLI generates TypeScript types directly from your database schema:
npx supabase gen types typescript --project-id "xyz" > database.types.ts
Then your queries are fully typed end-to-end:
import { createClient } from "@supabase/supabase-js";
import { Database } from "./database.types";
const supabase = createClient<Database>(url, key);
// Fully typed: result.data is Movie[], nullable columns are T | null,
// invalid column names are caught at compile time.
const { data, error } = await supabase
.from("movies")
.select("id, title, director")
.eq("year", 2024);
This is a major win for vibe coding because the AI gets full autocomplete, the compiler catches schema mismatches, and you don't end up with the model inventing column names that don't exist.
Batteries included: Postgres database, auth (with social providers, magic links, MFA), storage, edge functions (TypeScript, Deno-based), realtime subscriptions, vector embeddings. All in one dashboard.
Fast feedback loop: the Supabase CLI runs the whole stack locally in Docker, and supabase db push handles migrations. Edge functions hot reload during development.
Self-contained: yes, one project, one client.
Test ergonomics: because it's just Postgres underneath, you can use any Postgres testing tools you want. The CLI supports seeding and resetting the database between tests, and there are mature patterns for testing RLS policies.
Observability is solid and getting better. The dashboard has built-in log views for the API gateway, Postgres, edge functions, and auth, with filtering by status code, user, and path. OpenTelemetry support is rolling out, so you can pipe data into Datadog, Honeycomb, or Sentry.
So Which One Should You Actually Use?
All three are good, and they're good at different things. The right answer depends on what you're building.
Use Puter.js if you want a backend where you pay $0 regardless of scale. The User-Pays Model means each user covers their own usage, so there's no billing to wire up, no API keys to leak, and no risk of a viral user wiping out your budget. On top of that, it has the tightest feedback loop of the three and is especially strong for AI-first apps. The main areas to plan around are scheduled jobs and built-in observability — both are still maturing on the platform.
Use Firebase if you're building a mobile app, especially if you want push notifications, Crashlytics, and analytics out of the box. It's still the most polished mobile-first backend, and the training data depth means the AI writes Firebase code with very few hallucinations as long as you keep it on the modular API.
Use Supabase if you're building a real web product you intend to grow. The typed queries are a major advantage for vibe coding because they let the compiler do half the code review for you. And because it's just Postgres underneath, you have an exit ramp if you ever outgrow the platform.
The criteria at the top of this article are the lens. Apply them to whatever you're picking next, even something not on this list, and you'll usually end up with a backend that works with you instead of one that fights you every step of the way.
Related
Free, Serverless AI and Cloud
Start creating powerful web applications with Puter.js in seconds!
Get Started Now