Best ElevenLabs Alternatives (2026)
On this page
ElevenLabs has become the go-to platform for AI voice generation—and for good reason. Its voices are among the most natural-sounding on the market, its voice cloning works from short audio samples, and it supports 70+ languages with a growing suite of tools for dubbing, sound effects, music generation, and conversational AI agents. But ElevenLabs' subscription-based pricing, closed-source models, and lack of self-hosting options aren't the right fit for every project.
Here are five alternatives worth considering, each with a different take on text-to-speech.
1. Puter.js
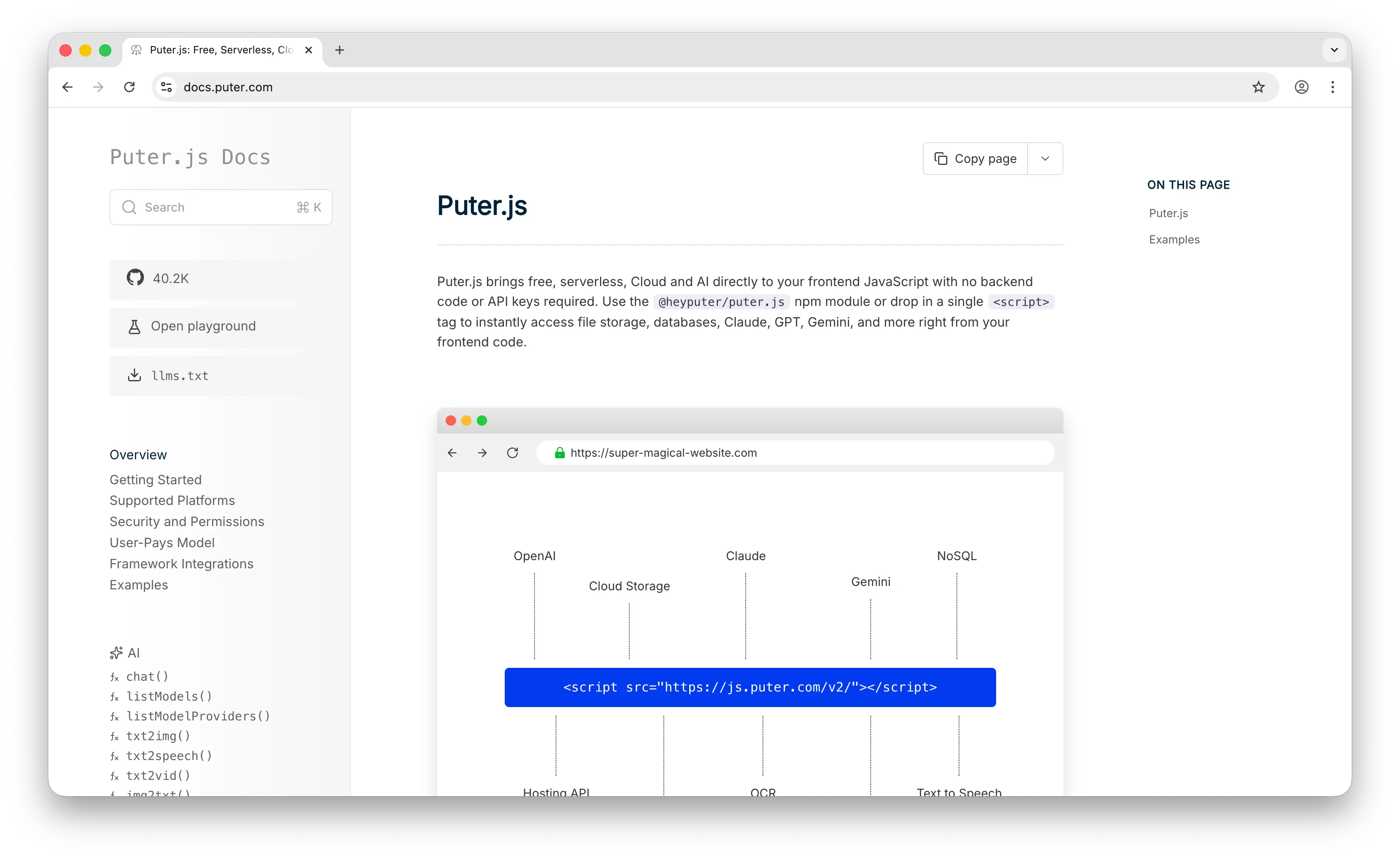
Puter.js is a JavaScript library for building web apps with built-in cloud services—AI, storage, databases, and authentication. For text-to-speech specifically, it acts as a unified frontend for multiple TTS providers, letting you call AWS Polly, OpenAI TTS, and even ElevenLabs through the same puter.ai.txt2speech() API without managing separate API keys for each.
What Makes It Different
The cost model is the headline: Puter.js uses a User-Pays Model where each end user covers their own TTS costs through their Puter account. As a developer, you pay nothing—no subscription, no per-character billing, no API key management. You can ship a voice-enabled app to thousands of users without a single dollar in TTS expenses on your end. With ElevenLabs, every character your users generate comes out of your plan's credit allowance.
Beyond the pricing model, Puter.js gives you provider flexibility. The same API call can route to AWS Polly (Standard, Neural, or Generative engines), OpenAI TTS (including gpt-4o-mini-tts with voice instructions), or ElevenLabs (Multilingual v2, Flash, voice conversion)—just by changing the provider parameter. It also supports speech-to-text (via GPT-4o Transcribe and Whisper), speech-to-speech voice conversion, and text-to-video, making it more of a full media toolkit than a single-purpose TTS service.
Key Differences from ElevenLabs
The trade-off is that Puter.js is a routing layer, not a voice engine. It doesn't have its own proprietary models—your voice quality is only as good as the provider you route to. The user-pays model works best in browser-based apps where users have Puter accounts; it's less natural for backend services or mobile apps. And you won't find ElevenLabs' dedicated features here: no professional voice cloning workflow, no dubbing studio, no voice library marketplace, and no built-in conversational AI agents.
Comparison Table
| Feature | Puter.js | ElevenLabs |
|---|---|---|
| API key required | No | Yes |
| Pricing model | User-pays (free for devs) | Subscription + pay-as-you-go |
| Markup | At cost (users pay providers) | Credit-based (plans from $5–$330/mo) |
| Voice quality | Depends on provider (Polly, OpenAI, ElevenLabs) | Industry-leading (proprietary models) |
| Voice cloning |  (via ElevenLabs provider) (via ElevenLabs provider) |
Instant + Professional |
| Voice marketplace |  |
|
| Multi-provider support | (Polly, OpenAI, ElevenLabs) |
(proprietary only) |
| Speech-to-text | (GPT-4o, Whisper) |
|
| Voice conversion (STS) | |
|
| Dubbing / localization | |
|
| Sound effects / music | |
|
| Conversational AI agents | |
|
| Languages | Depends on provider | 70+ |
| Open source | |
|
| Best for | Frontend devs who want zero-cost TTS integration | Teams needing premium voice quality and full audio suite |
2. OpenAI TTS
OpenAI TTS is the text-to-speech offering from OpenAI, available through their Audio API. It includes three models: tts-1 (optimized for low latency), tts-1-hd (optimized for quality), and the newer gpt-4o-mini-tts (built on GPT-4o mini with instruction-following capabilities).
What Makes It Different
The standout feature of OpenAI TTS is the gpt-4o-mini-tts model's instruction support. For the first time, developers can tell the model not just what to say but how to say it—using natural language instructions like "Speak in a cheerful and positive tone" or "Read this like a dramatic audiobook narrator." This makes it the most steerable TTS API on the market without requiring SSML markup or complex parameter tuning.
OpenAI TTS is also significantly cheaper than ElevenLabs. Standard TTS costs $15 per million characters, and HD costs $30 per million characters—compared to ElevenLabs, where equivalent usage on a subscription plan can run substantially higher. The gpt-4o-mini-tts model uses token-based pricing at approximately $0.015 per minute of generated audio, making it one of the most cost-effective options for high-volume use cases.
It provides 13 built-in voices (Alloy, Ash, Ballad, Coral, Echo, Fable, Nova, Onyx, Sage, Shimmer, Verse, Marin, and Cedar), supports multiple output formats (MP3, Opus, AAC, FLAC, WAV, PCM), and offers real-time streaming with low latency.
Key Differences from ElevenLabs
OpenAI TTS does not support voice cloning. You're limited to the 13 preset voices—there's no way to upload your own voice or create custom voices (though this is on OpenAI's roadmap). The voice selection is far smaller than ElevenLabs' library of thousands of community voices. It also lacks ElevenLabs' dubbing, sound effects, and long-form audio capabilities. The older tts-1/tts-1-hd models have a 4,096-character-per-request limit, while gpt-4o-mini-tts has a 2,000-token input limit—both require chunking for longer content. Extended outputs beyond 1–2 minutes may also exhibit occasional pauses or glitches.
Comparison Table
| Feature | OpenAI TTS | ElevenLabs |
|---|---|---|
| Pricing model | Pay-as-you-go (per character/token) | Subscription + pay-as-you-go |
| Cost (approx.) | $15–$30 per 1M characters | $198–$220 per 1M characters (Pro: $99/500K, Creator: $22/100K) |
| Free tier | $5 API credits for new accounts | 10,000 credits/month (~10 min) |
| Voice instruction/steering | (gpt-4o-mini-tts) |
Limited (SSML, text tags) |
| Voice cloning | |
Instant + Professional |
| Voice selection | 13 built-in voices | Thousands (library + marketplace) |
| Streaming support | |
|
| Speech-to-text | (GPT-4o Transcribe, Whisper) |
|
| Dubbing / localization | |
|
| Sound effects / music | |
|
| Conversational AI agents | (separate Realtime API product) |
|
| Languages | Multiple (quality varies by language) | 70+ |
| SSML support | (uses natural language instructions) |
(uses text tags) |
| Output formats | MP3, Opus, AAC, FLAC, WAV, PCM | MP3, PCM, μ-law, and more |
| Best for | Cost-conscious devs in the OpenAI ecosystem | Teams needing premium voices and voice cloning |
3. Deepgram
Deepgram is a voice AI platform best known for its industry-leading speech-to-text (Nova-3), but its Aura-2 text-to-speech model has become a strong contender, particularly for real-time voice agent use cases.
What Makes It Different
Deepgram's primary differentiator is ultra-low latency. Aura-2 delivers sub-200ms baseline time-to-first-byte, with optimized performance reaching as low as 90ms. This makes it one of the fastest TTS APIs available, purpose-built for real-time conversational AI where even small delays feel unnatural.
Because Deepgram offers both STT (Nova-3) and TTS (Aura-2) on the same platform, developers get a unified voice pipeline with fewer handoffs, lower overall latency, and consistent pronunciation across what the agent hears and what it says. Deepgram also offers a dedicated Voice Agent API for building end-to-end voice agents, with pricing tiers from $0.04 to $0.16 per minute.
Another key advantage is on-premises deployment. For enterprises with strict data privacy, compliance, or latency requirements, Deepgram can be deployed in your own infrastructure—something ElevenLabs does not offer.
Deepgram also excels at domain-specific accuracy, ensuring correct pronunciation for industry terminology in healthcare, finance, legal, and other specialized fields.
Key Differences from ElevenLabs
Deepgram's TTS voice catalog is more limited—40+ English voices and 10+ Spanish voices across 7 languages total—compared to ElevenLabs' 70+ language support and thousands of voices. There is no voice cloning capability; Deepgram focuses on custom pronunciation and domain-specific tuning rather than replicating a specific person's voice. It also lacks ElevenLabs' content creation tools like dubbing, sound effects, music generation, and the voice marketplace.
Comparison Table
| Feature | Deepgram | ElevenLabs |
|---|---|---|
| Pricing model | Pay-as-you-go (per character) | Subscription + pay-as-you-go |
| TTS cost | $0.030 per 1,000 characters | Varies by plan (credit-based) |
| Free tier | $200 in free credits (one-time) | 10,000 credits/month (~10 min, recurring) |
| Latency | Sub-200ms (90ms optimized) | ~75ms (Flash v2.5), higher for quality models |
| Voice cloning | |
Instant + Professional |
| Voice selection | 40+ English, 10+ Spanish | Thousands (library + marketplace) |
| Speech-to-text | Industry-leading (Nova-3) |
|
| Unified STT + TTS pipeline | Shared streaming infrastructure |
Both available, separate engines |
| Voice Agent API | |
|
| Domain-specific accuracy | (healthcare, finance, legal) |
Limited |
| On-premises deployment | |
|
| Dubbing / localization | |
|
| Sound effects / music | |
|
| Languages | 7 (expanding) | 70+ |
| Best for | Real-time voice agents and enterprise STT+TTS pipelines | Content creators and teams needing premium voice quality |
4. Amazon Polly
Amazon Polly is AWS's fully managed text-to-speech service, offering four voice engines—Standard, Neural, Long-Form, and Generative—with 100+ voices across 40+ languages.
What Makes It Different
Amazon Polly's biggest advantage is its deep integration with the AWS ecosystem. If you're already using AWS services like Lambda, S3, DynamoDB, or Connect, Polly fits seamlessly into your existing infrastructure without adding another vendor. Generated audio can be stored in S3 and redistributed at no extra cost.
Polly offers the broadest language and voice coverage of any service on this list, with 100+ voices in 40+ languages and variants. It recently expanded its Generative engine with 10 new highly expressive voices and introduced a Bidirectional Streaming API that allows text to be streamed into Polly while synthesized audio is returned simultaneously—ideal for feeding LLM output directly into speech synthesis.
Polly also provides robust SSML support for fine-grained control over pronunciation, emphasis, pauses, speech rate, and pitch. Its Newscaster speaking style makes certain Neural voices sound like professional news anchors. For enterprises, Polly supports custom Brand Voices—purpose-built voices that are unique and exclusive to your organization.
At just $4 per million characters for Standard voices, $16 per million characters for Neural voices, and $30 per million characters for Generative voices (the engine most comparable to ElevenLabs' quality), Polly is one of the most cost-effective TTS options available, especially at scale. The free tier includes 5 million Standard characters or 1 million Neural characters per month for 12 months. Additionally, as of July 2025, new AWS customers receive up to $200 in AWS Free Tier credits that can be applied to Polly and other services.
Key Differences from ElevenLabs
Polly's voice quality, while good, does not match ElevenLabs' naturalness and expressiveness for most use cases. Several user reviews note that voices can sound more robotic compared to ElevenLabs or even Azure Neural TTS. Polly does not offer voice cloning (except through the enterprise Brand Voice program, which requires a custom engagement). The sign-up process requires an AWS account, which some users find cumbersome compared to simpler API-first services. Polly also lacks creative audio tools like sound effects, music generation, dubbing, or a voice marketplace.
Comparison Table
| Feature | Amazon Polly | ElevenLabs |
|---|---|---|
| Pricing model | Pay-as-you-go (per character) | Subscription + pay-as-you-go |
| Cost (Neural) | $16 per 1M characters | $198–$220 per 1M characters (Pro: $99/500K, Creator: $22/100K) |
| Cost (Generative) | $30 per 1M characters | Included in plans |
| Free tier | 5M Standard / 1M Neural chars/month (12 months) + $200 AWS credits for new accounts | 10,000 credits/month (~10 min, recurring) |
| Voice engines | 4 (Standard, Neural, Long-Form, Generative) | Multiple (Multilingual v2, Flash, Turbo) |
| Voices | 100+ | Thousands (library + marketplace) |
| Voice cloning | (Brand Voice via enterprise only) |
Instant + Professional |
| SSML support | Extensive |
(text tags, not SSML) |
| Bidirectional streaming | (Generative engine) |
|
| Speech Marks | (word/sentence-level timing) |
Limited |
| Languages | 40+ | 70+ |
| Newscaster style | |
|
| Custom Brand Voices | (enterprise) |
|
| Dubbing / localization | |
|
| Sound effects / music | |
|
| Ecosystem integration | AWS (Lambda, S3, Connect, etc.) | Standalone API |
| HIPAA eligible | |
Enterprise only |
| Best for | Teams on AWS needing cost-effective, scalable TTS | Teams needing premium voice quality and creative tools |
5. Chatterbox
Chatterbox is a family of open-source text-to-speech models by Resemble AI, released under the MIT license. It includes three model variants: the original Chatterbox (500M parameters), Chatterbox-Multilingual (550M, 23 languages), and Chatterbox-Turbo (350M, optimized for speed).
What Makes It Different
Chatterbox is the only fully open-source option on this list, and it's not a compromise—it's competitive with the best commercial offerings. In blind evaluations conducted by Podonos using English-language samples, 63.75% of listeners preferred Chatterbox over ElevenLabs for naturalness and emotional resonance. The test used zero-shot generation with identical text inputs and 7–20 second reference clips, with no prompt engineering or audio post-processing on either side. It's worth noting the evaluation was English-only and limited in scope, but the results are still striking for a free, open-source model.
The standout feature is emotion exaggeration control, a first among open-source TTS models. A single parameter (0.0 to 2.0) lets you dial emotional expressiveness from monotone to dramatically expressive—no SSML markup, no text tags, just a slider. Combined with zero-shot voice cloning from just 7–20 seconds of reference audio (as little as 5 seconds minimum), this gives developers a level of creative control that even ElevenLabs doesn't offer in the same way.
Chatterbox-Turbo is particularly impressive: it uses a distilled one-step decoder (down from 10 diffusion steps), delivering faster-than-realtime inference with significantly lower compute and VRAM requirements. It also supports paralinguistic tags like [laugh], [cough], and [chuckle] natively, adding realistic non-speech sounds to generated audio.
Every audio file generated by Chatterbox includes Resemble AI's PerTh (Perceptual Threshold) watermark—an imperceptible neural watermark that survives MP3 compression and audio editing, enabling detection of synthetic content without degrading audio quality.
Being MIT-licensed, Chatterbox can be self-hosted on your own GPU infrastructure with zero API fees—making it essentially free to run at any scale. For teams that prefer a managed solution, Resemble AI also offers a hosted Chatterbox service with competitive pricing.
Key Differences from ElevenLabs
Chatterbox requires your own GPU hardware for self-hosting (an NVIDIA GPU with sufficient VRAM), which adds operational complexity compared to ElevenLabs' fully managed API. The English-only Turbo model is the most capable, while multilingual support across 23 languages is available but less mature than ElevenLabs' 70+ language coverage. Chatterbox lacks ElevenLabs' broader audio platform features like dubbing, sound effects, music generation, conversational AI agents, and the voice marketplace. It's a TTS model, not a full audio platform.
Comparison Table
| Feature | Chatterbox | ElevenLabs |
|---|---|---|
| Pricing model | Free (self-hosted) / Hosted plans available | Subscription + pay-as-you-go |
| Cost | $0 (self-hosted with your GPU) | Plans from $5–$330/mo |
| License | MIT (fully open source) | Proprietary |
| Voice quality | Competitive (63.75% preferred in English blind tests) | Industry-leading |
| Voice cloning | Zero-shot (7–20 sec recommended, 5 sec minimum) |
Instant + Professional |
| Emotion control | Exaggeration parameter (0.0–2.0) |
Limited (text tags) |
| Paralinguistic tags | [laugh], [cough], [chuckle] (Turbo) |
|
| Model variants | 3 (Original, Multilingual, Turbo) | Multiple (Multilingual v2, Flash, Turbo) |
| Self-hosting | |
|
| Audio watermarking | PerTh (built-in) |
(optional) |
| Speech-to-text | |
|
| Dubbing / localization | |
|
| Sound effects / music | |
|
| Voice marketplace | |
|
| Languages | 23 (Multilingual) / English (Turbo) | 70+ |
| Conversational AI agents | |
|
| Best for | Devs who want full control, zero API costs, and competitive quality | Teams needing a managed, full-featured audio platform |
Which Should You Choose?
Choose Puter.js if you're building a web app and want to add TTS features without any backend or API costs. The user-pays model is ideal for frontend developers who don't want to worry about covering their users' voice generation costs, and the multi-provider support gives you flexibility.
Choose OpenAI TTS if you need cost-effective, high-quality TTS with the unique ability to steer voice delivery through natural language instructions. It's the best option for teams already in the OpenAI ecosystem who want a simple, affordable API without the complexity of voice cloning or SSML.
Choose Deepgram if you're building real-time voice agents and need the fastest possible latency with a unified STT + TTS pipeline. Its sub-200ms response time, Voice Agent API, domain-specific accuracy, and on-premises deployment option make it the strongest choice for enterprise conversational AI.
Choose Amazon Polly if you're already on AWS and need scalable, cost-effective TTS with the broadest language coverage. Its deep AWS integration, SSML support, HIPAA eligibility, and generous free tier make it a practical choice for enterprises with existing cloud infrastructure.
Choose Chatterbox if you want full control over your TTS infrastructure with zero API costs. Its MIT license, competitive voice quality, emotion exaggeration control, and zero-shot voice cloning make it the best open-source option for developers who can self-host on GPU hardware.
Stick with ElevenLabs if you need the most natural-sounding voices, professional voice cloning, 70+ language support, and a complete audio platform (dubbing, sound effects, music generation, conversational agents, voice marketplace). It remains the most comprehensive option for teams that prioritize voice quality and creative audio capabilities above all else.
Conclusion
The best ElevenLabs alternatives are Puter.js, OpenAI TTS, Deepgram, Amazon Polly, and Chatterbox. Each takes a different approach to text-to-speech—from Puter.js's zero-cost frontend integration to OpenAI's steerable instructions to Deepgram's ultra-low latency to Amazon Polly's AWS-native scalability to Chatterbox's open-source freedom. Whichever platform you choose, the best option is the one that fits your stack, your budget, and how your users will interact with voice in your app.
Related
Free, Serverless AI and Cloud
Start creating powerful web applications with Puter.js in seconds!
Get Started Now